ST-GCN
论文:2018AAAI《Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition》
Contributions

本文的主要贡献就是第一次将图的网络应用在骨架模型上用于行为分析任务,然后提出了一些设计特殊的特殊卷积操作的规范,给后来的相关工作提供借鉴意义。
Method

构建骨骼时空图G= (V,E),帧数为T,每一帧上关节点数为N.在图中,节点矩阵集合$V={v_{ti}|t=1,…,T,i=1,…N}$ ,包括骨骼序列上的所有的关节点。
使用两步构建骨骼序列的时空图。第一步,帧与帧之间的边表示人体对应骨骼点的时序关系;第二步,在每一帧内部,按照人体的自然骨架连接关系构造空间图。

进入完全的ST-GCN 之前,首先看单帧上的graph CNN model。在这种情况下,在时刻t ,单张视频帧的情况下,将会有N 个骨骼节点 Vt,并且有骨骼边界。我们回忆在2D 自然图像或者feature maps 上的卷积操作,卷积操作的输出仍然是2D 的网格。当步长为1,并且设置合适的padding 时,输出的feature maps 可以和输入拥有相同的大小。我们在接下来的讨论中,都是基于这个假设。给定一个kernel size 为K*K 的卷积操作,通道个数为c 的输入 featuremaps,在位置 x 处的单个通道的输出值为:fout
P 是采样函数,列举了位置 x 的近邻。加权函数w提供了一个权重向量,来计算其与采样的输入向量的内积。由于加权函数与位置x 无关,所以,滤波器的权重可以在图像中进行共享。在图像领域,标准的卷积在图像领域可以通过编码矩形网格,在 graph 上的卷积操作可以定义为:将上述定义拓展到存在于 spatial graph Vt 的输入特征图上.
本文中D=1,D的取值可以变化,情况复杂,future work
对于加权函数,在 2D 卷积中,一个固定的 grid 自然的存在于中心位置,相邻像素点拥有一个固定的空间次序,而在graph中是没有这种顺序的,文中建议不用给定每一个近邻节点一个特定的 labeling,我们简单的将骨骼节点的近邻集合划分为固定个数的 K 个子集,每一个子集有一个 label。
正则项Z对应子集的基数,是用来平衡不同子集对输出的贡献

在上述Spatialgraph CNN 的基础上,我们现在开始将其拓展到时空结构上。在构建图的时候,temporal aspect 我们是直接时序上相同的节点连接起来的。这确保我们可以定义一种非常简单的策略将空间上的图卷积CNN 拓展到 时空域。我们将近邻节点拓展到包含时序连接的节点
时空图卷积:只需要对应修改采样函数和权重映射函数就可以扩展到时空图上,设置采样区域为相邻几帧。权重映射函数根据相邻帧的图有序特点,因此可以设置如下映射函数,当作一种对应寻址的操作,即第几个维度上的第几个矩阵元素。
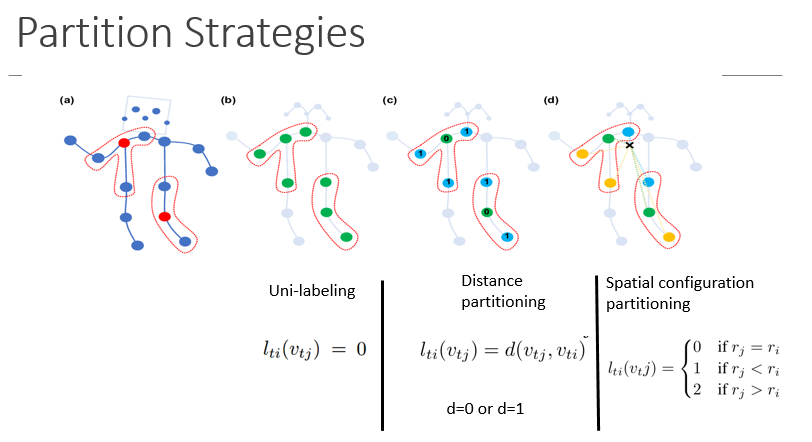
给定spatialtemporal graph convolution 的高层定义,设计一种partitioningstrategy 来执行 标签映射函数l
(a)输入骨骼的框架示例。身体关节以蓝点表示。D=1的卷积核感受野由红色的虚线画出。(b)单标签划分策略。其中近邻的所有节点标签相同(绿色)。(c)距离划分。这两个子集是距离为0 的根节点本身,和距离为1 的根节点相邻节点(蓝色)。(d)空间构型划分。根据节点到骨架重心(图中黑色十字)的距离和到根节点(绿色)的距离的比较进行标记。向心节点(蓝色)到骨架重心的距离比根节点到骨架重心的距离短,而离心节点(黄色)到骨架重心的距离比根节点长

在single-frame的情况下,用第一种分割策略的st-gcn 可以用左边的公式进行表达:
对于多个子集的划分策略,用右边的公式表达,此时邻接矩阵被分解为多个矩阵 Aj
通过邻接矩阵左乘特征矩阵,可以实现特征的聚合操作,然后再右乘权重矩阵,可以实现加权操作。
多个输出通道的权重向量堆叠起来构成了权重矩阵
$\alpha$是为了避免有的行empty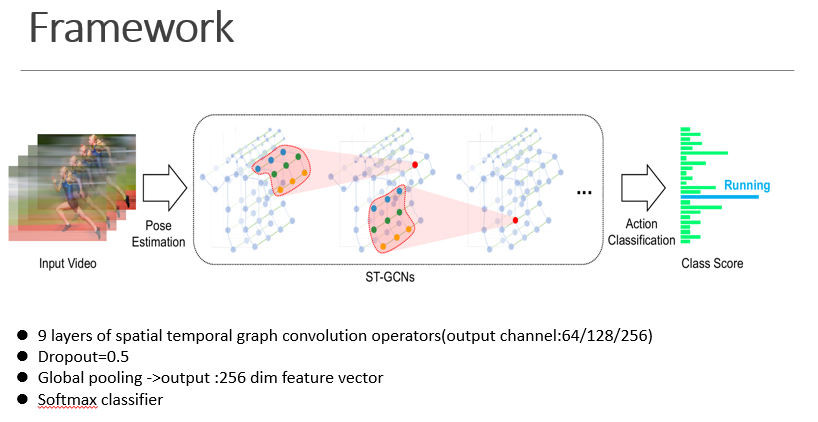
基于骨骼的数据可以从运动捕捉设备或视频的姿态估计算法中获得。通常来说,数据是一系列的帧,每一帧都有一组联合坐标。给定2D 或 3D 坐标系下的身体关节序列,我们就能构造一个时空图。其中,人体关节对应图的节点,人体身体结构的连通性和时间上的连通性对应图的两类边。因此,ST-GCN 的输入是图节点的联合坐标向量。对输入数据应用多层的时空图卷积操作,可以生成更高级别的特征图。然后,它将被标准的SoftMax分类器分类到相应的动作类别。整个模型用反向传播进行端对端方式的训练。ST-GCN模型由九层时空图卷积组成。前三层输出64通道数,中间三层输出128通道,最后三层输出256层通道数。一共有9个时间卷积核,在每一个ST-GCN使用残差链接,使用dropout进行特征正则化处理,将一半的神经元进行dropout处理。第4、7层的时间卷积层设置为poling层。最后将输出的256个通道数的输出进行全局pooling,并由softmax进行分类。
当ST-GCN作为输入的时候,对于一个batch 的视频,我们可以用一个5 维矩阵表示。
N代表视频的数量,通常一个batch 有 256个视频(其实随便设置,最好是 2的指数)。
C代表关节的特征,通常一个关节包含等 3 个特征(如果是三维骨骼就是4 个)。
T代表关键帧的数量,一般一个视频有150 帧。
V代表关节的数量,通常一个人标注18 个关节。
M代表一帧中的人数,一般选择平均置信度最高的2 个人。
所以,OpenPose的输出,也就是 ST-GCN的输入
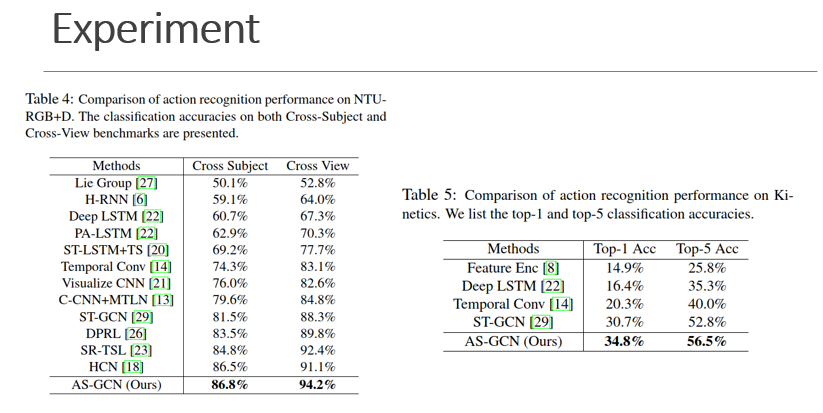
Result
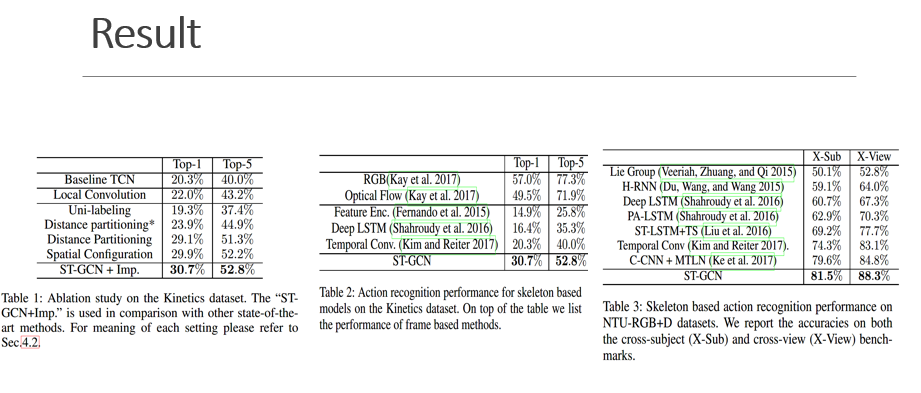
图一是三种划分策略的消融实验,Imp是加了maskM, mask 相当于attention操作,根据图中Es上边缘学习的重要性来缩放节点特征对于相邻节点的重要性。(future work)
第三种策略实际上也包含了对末肢关节赋予更多关注的思想,通常距离重心越近,运动幅度越小,同时能更好的区分向心运动和离心运动。

2s-AGCN
论文:2019CVPR《Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition》
Contributions

1.ST-GCN中使用的骨架图是启发式预定义的,并且仅表示人体的物理结构。因此,它不能保证对动作识别任务是最优的。例如,双手之间的关系对于识别诸如“拍手”和“阅读”之类的类很重要。然而,ST-GCN很难捕捉到双手之间的依赖关系,因为它们在预先定义的基于人体的图形中彼此相距很远。
2.GCN的结构是层次结构,不同的层次包含多级语义信息。然而,ST-GCN中应用的图的拓扑结构在所有层上都是固定的,缺乏对所有层中包含的多级语义信息进行建模的灵活性和能力;
3.对于不同行为类别的所有样本,一个固定图结构可能不是最优的。对于“擦脸”和“摸头”这类类别,手和头之间的联系应该更紧密,但对于其他一些类别,如“跳起来”和“坐下来”则不是这样。这一事实表明,图结构应该依赖于数据,然而,ST-GCN不支持这种依赖性。
为了解决上述问题,本文提出了一种新的自适应图卷积网络。

ST-GCN中另一个值得注意的问题是,每个顶点上的特征向量只包含关节的二维或三维坐标,可以将其视为骨架数据的一阶信息。然而,代表两关节间骨骼特征的二阶信息并没有被利用。通常情况下,骨骼的长度和方向对于动作识别来说自然更具信息性和识别性。为了利用骨骼数据的二阶信息,将骨骼的长度和方向表示为从其源关节指向目标关节的向量。与一阶信息相似,矢量被输入一个自适应图卷积网络来预测动作标签。同时,提出了一种融合一阶和二阶信息的双流框架,进一步提高了系统的性能。
(1)提出了一种自适应图卷积网络,以端到端的方式自适应地学习不同GCN层和骨架样本的图的拓扑结构,能够更好地适应GCN的动作识别任务和层次结构。(2)骨架数据的二阶信息采用双流框架显式地表示并与一阶信息相结合,对识别性能有显著提高。(3)在两个大规模的基于骨架的动作识别数据集上,所提出的2s-Agcn大大超过了最先进的水平。
Method
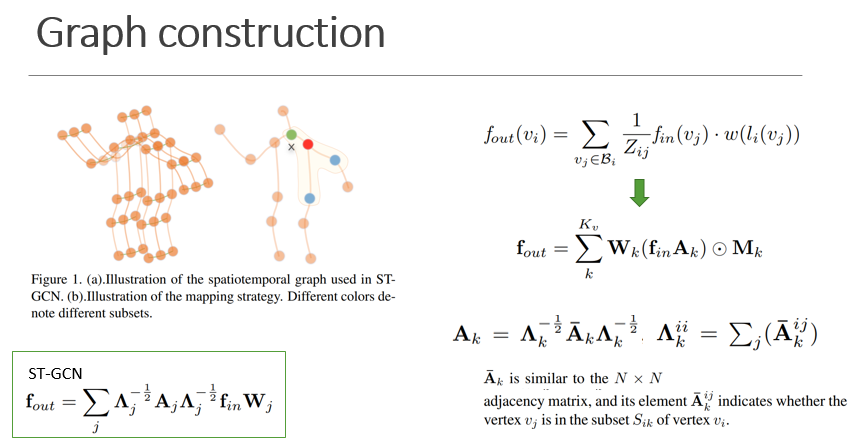
首先还是图的构建,采用的是ST-GCN定义的图构建方法,划分策略采用的是基于空间构型的
$K_v$为kernel size,
$M_k$ is an N × N矩阵,相当于attention的作用,表示每个节点的重要程度
点乘

前面的式子中图的拓扑结构是固定的,有$A_k$和$M_k$决定,$A_k$表示两点之间是否有链接,$M_k$表示连接的强弱,为了让图的结构变得自适应,变换成右边,使得图的拓扑结构和参数一样在训练过程中端到端的进行优化.
$B_k$是训练得到的,通过数据驱动的方式,模型可以学习完全针对识别任务的图形,并且针对不同层中包含的不同信息更加个性化。矩阵中的元素可以是任意值。它不仅表明两个关节之间存在连接,而且还表明连接的强度。它可以起到Mk执行的注意机制的相同作用。 然而,原始注意矩阵Mk是点乘以Ak,这意味着如果中的一个元素为0,则无论的值如何,它总是为0。因此,它无法生成原始物理图中不存在的新连接。从这个角度来看,Bk比Mk更灵活。
$C_k$是一个数据相关图,它可以学习每个样本的唯一graph表示。为了确定两个顶点之间是否存在连接以及连接的强度,应用标准化的embedding高斯函数来计算两个顶点的相似度
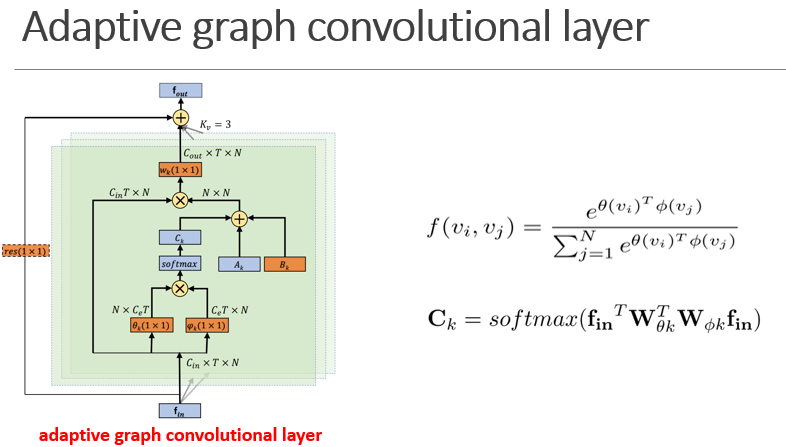
自适应图卷积层的图示。每层中总共有三种类型的graph,即$A_k$,$B_k$和$C_k$。橙色框表示该参数是可学习的。1x1表示卷积的内核大小。$K_v$表示子集的数量。 ⊕表示元素总和。 ⊗表示矩阵乘法。仅当$C_in$与$C_out$不同时,才需要左侧的residual box(虚线)
上式函数f表示正则化embeded高斯函数,用来计算两个点之间的相似度,左图中给定输入的特征图为Cin×T ×N, 首先转换到特征空间$C_e×T ×N$,通过 θ and φ,然后将他们reshape到$N \times C_eT$和$C_eT \times N$矩阵中,将两个矩阵相乘得到相似度矩阵$C_k$, $Ckij$ 表示点i和j的相似度,所以$C_k$中的元素值在0-1之间,可以表示两个结点之间的软连接关系,然后将正则化高斯项与softmax操作得到最终$Ck$,$Wθ$和 $W_φ$分别表示embedding函数中θand φ的参数
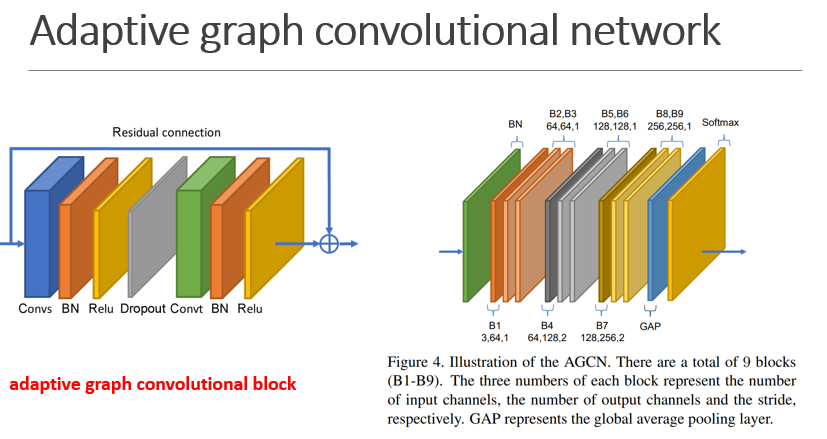
Convs 表示spatial GCN, and Convt表示temporal GCN,后面都接一个BN和ReLU,每个block都有一个shortcut
右图是AGCN网络结构,一共包含9个block,每个块下面三个数字分别表示输入通道的数量,输出通道的数量和步幅,最后接一个GAP,送入softmax分类器
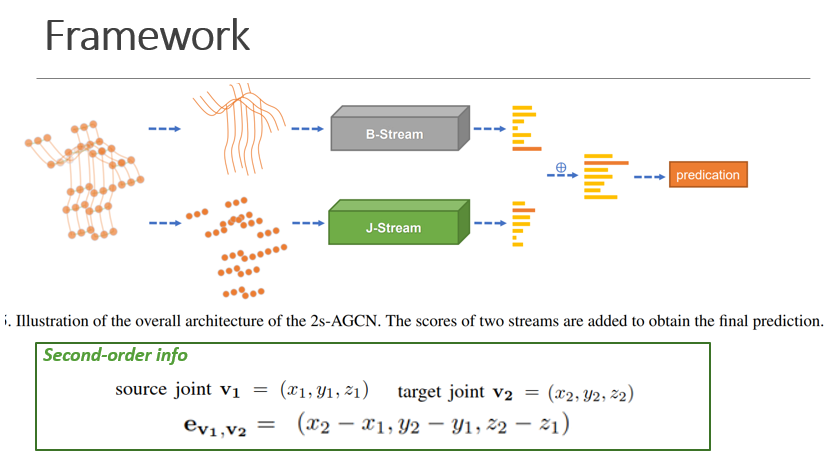
论文提出的2stream 网络结构
关节点数据送入J-stream
骨骼数据送入B-stream
最后两路的输出相加后送入softmax中得到结果
Result
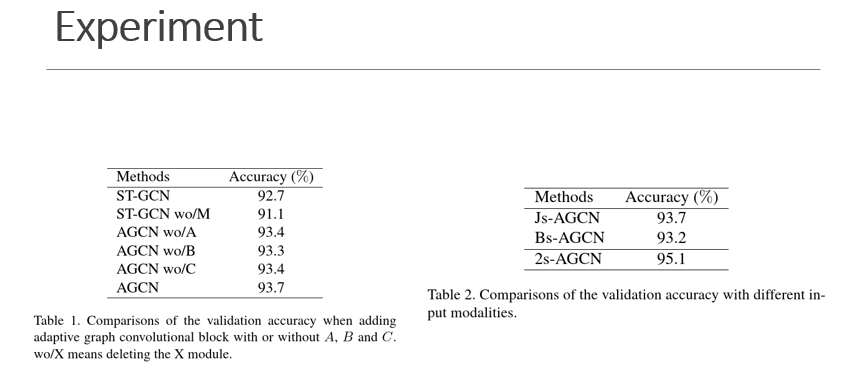
消融实验,左边证明$A_k,B_k,C_k$的重要性,是adaptive的作用
右边表示双流的重要性
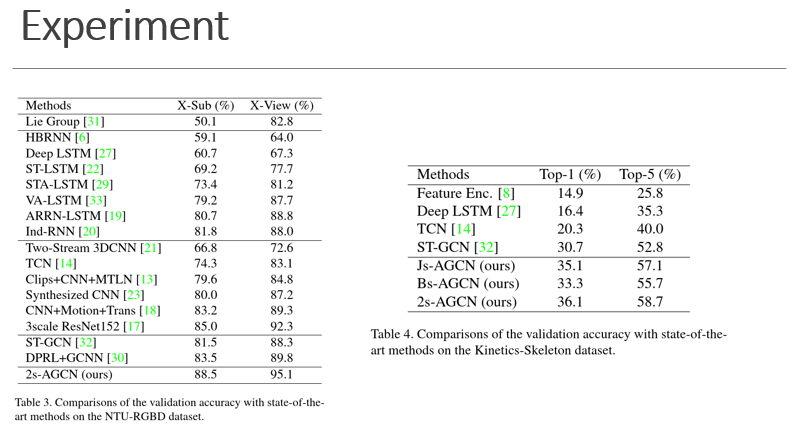
AS-GCN
论文:2019CVPR《Actional-Structural Graph Convolutional Networks for Skeleton-based
Action Recognition》
Contributions

本文的贡献主要是提出a-link推理模块用于捕捉动作相关的潜在关系,提出动作-结构图卷积网络用于获取时空信息进行行为分析,并提出了一个未来姿态预测头用来预测未来姿态
Method
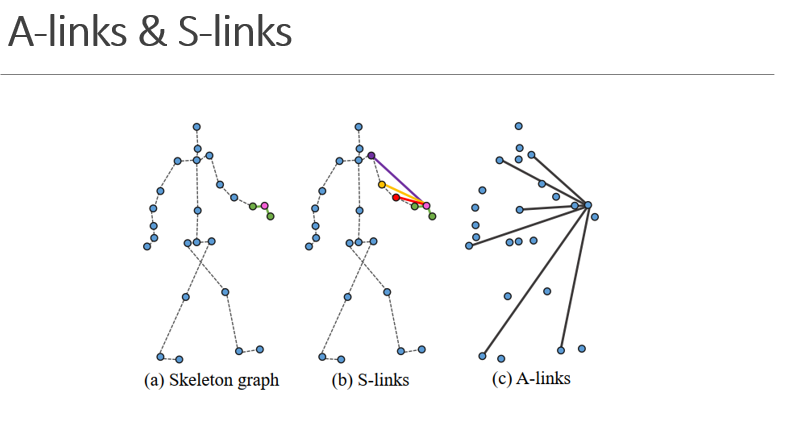
上图表示行走状态的骨架图
以往的方法只捕捉关节之间的局部物理依赖关系,可能忽略了关节间的隐式关联,提出通过A-link来发掘潜在的关节之间的联系,通过s-link来发掘骨骼图的高阶关系。
图b中S-links表示右手可以连接左臂关节点,而ST-GCN只关注一阶近邻的关节点
图c中A-links捕捉远距离的,直接从动作捕获特定于动作的潜在依赖关系,比如走路时,手和脚是相关的
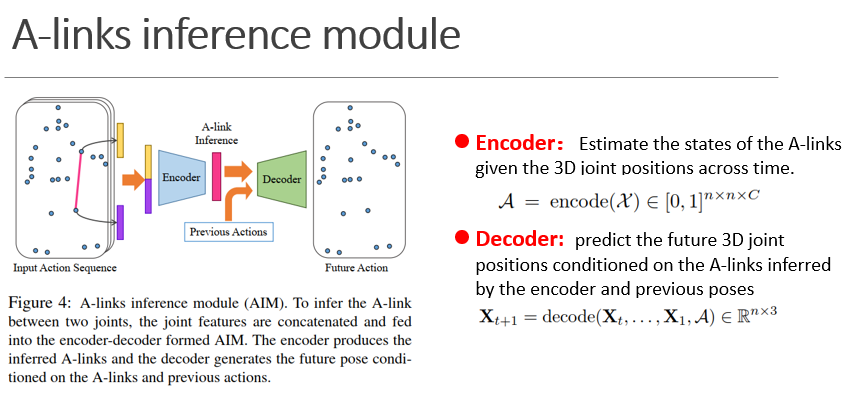
A-Link实际上就是每个关节和其他所有关节的连接,通过一个编码-解码器来学习这些连接的权重,进而发掘关节之间的潜在联系。
Encoder用来通过给定的关节点坐标得到A-links,decoder通过A-link得到未来关节点坐标的预测,上图中左侧黄色和紫色分别代表某一帧的原始的joints features和links features,将两种类型的特征反复迭代更新(encoder),可以实现特征在关节和边中的流动传播,最终得到一个概率权重矩阵。将这个矩阵和该帧之前的所有时刻的帧信息结合起来,通过一个decoder来预测下一时刻的关节位置。这样就能通过反向传播的方式来不断的迭代更新网络参数,实现对网络的训练。在网络得到初步的训练后,将decoder去掉,只使用前半部分抽取A-link特征,用于动作分类任务的进一步训练。

传统的图卷积网络中,每个节点只将自己的信息传播给邻居节点,这会导致节点感受野较小,不利于获取长距离的连接信息。通过对邻接矩阵取一定次数的幂,可以扩大感受野,L为阶数
左边的式子是一阶领域内的spatialgraph convolution操作,右边扩展到L阶,L大于等于1
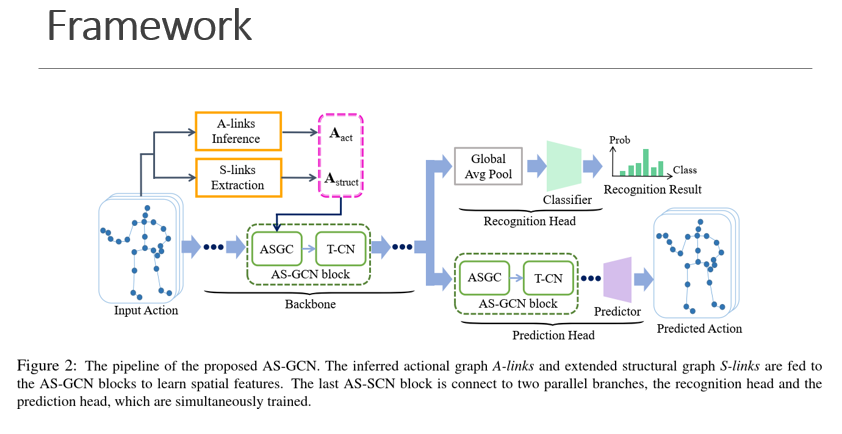
AS-GCN的网络结构,采用多任务处理
将A-Link和S-link加权结合起来作为GCN的输入。将GCN和Temporal-GCN结合,得到AS-GCN模块,作为基本网络(Backbone)。接不同的后端网络,可以分别实现分类功能和预测功能,识别头是通过GAP和softmax得到识别的类型,预测头不仅可以促进自监督,还可以提高识别准确率。
核心思想:
- 从原始的坐标信息中提取出A-links特征信息作为输入特征,具有更高的可识别度
- 通过对邻接矩阵取多次幂来扩大节点的感受域。
- 多个block叠加,通过提高复杂度来提高识别能力。
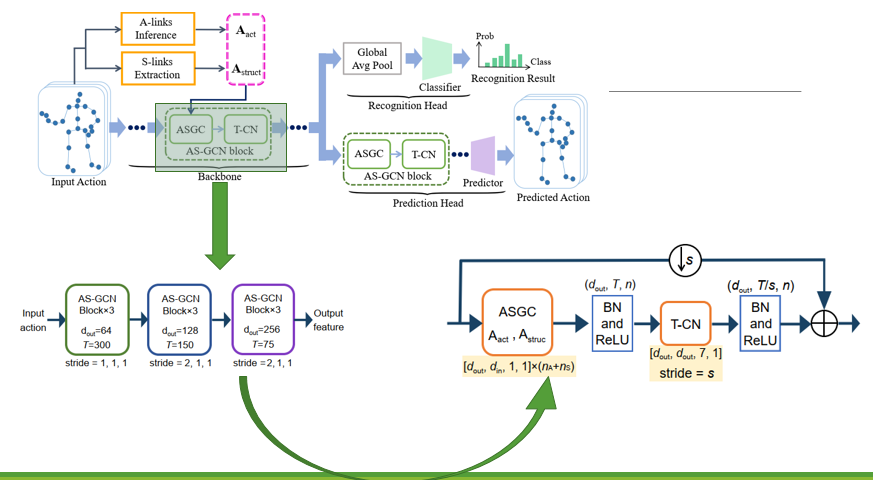
左下角是backbone的示意图,由9个AS-GCN块组成,右边是具体的block里面的结构,ASGC+TCN
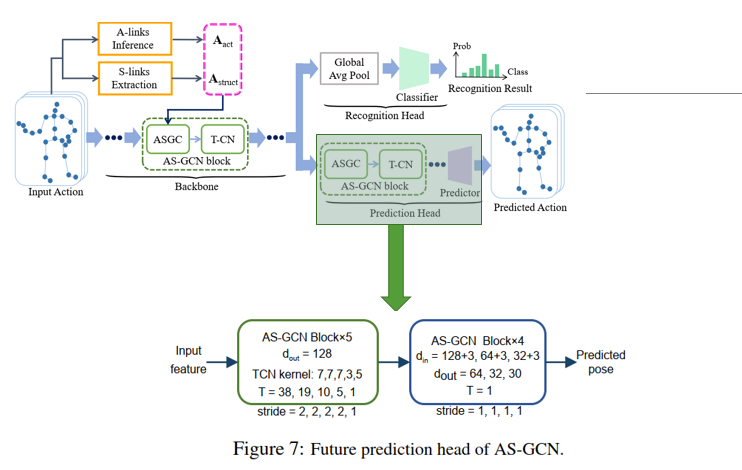
预测头的结构,就是5个AS-GCN block+TCN堆叠,再接4个AS-GCN模块组成,解码高层语义特征,得到预测未来的关节点坐标
Result