GhostVLAD
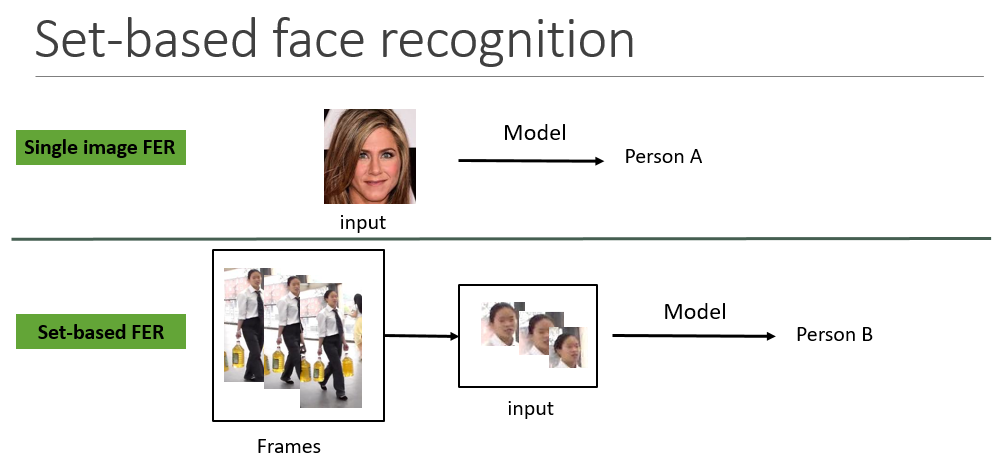
我们熟悉的人脸识别的一般流程是输入一张图片,然后经过人脸检测对齐以及特征提取后,进行人脸识别或者验证,一张图像是很好获取的,但是在现实中,比如监控视频中,由于角度和距离以及设备等原因,会得到很多姿态、光照和模糊度不同的图像,高质量的人脸图像一般难以获取,有时候还可能需要我们通过一定的算法从中选一张成像质量相对较好的进行识别,那么有一个直观的想法就是,能否直接基于多张图像的集合直接进行人脸识别呢?
GhostVLAD是ACCV2018年的一篇基于集合的人脸识别论文
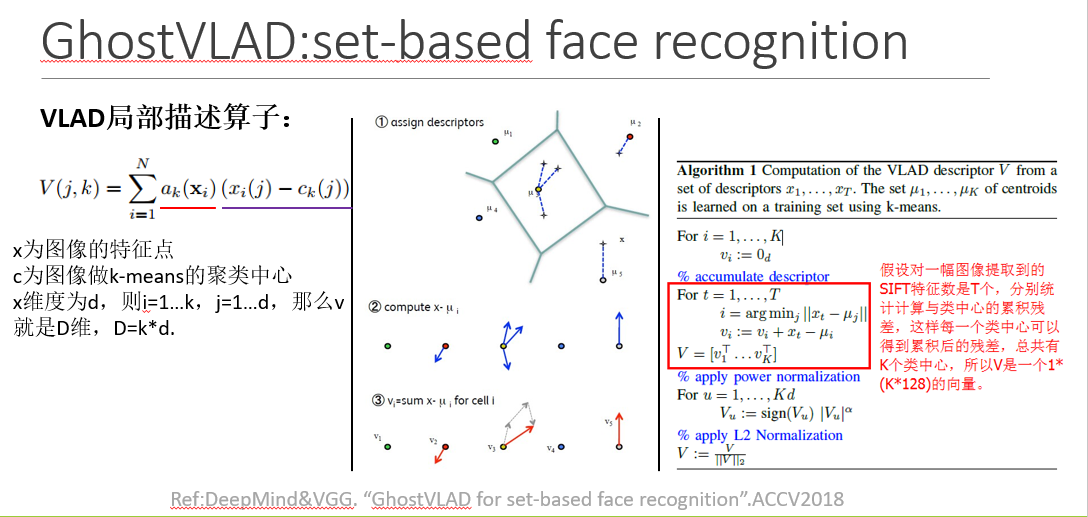
VLAD是一种局部描述算子,主要应用在图像大规模检索领域,在于提出一种图像表示方法,在拥有合理的向量维度下,具有很好的搜索准确率
左边的式子是VLAD的计算公式,ak为0或者1,当ck为xi的最近聚类中心时,ak=1,其余为0。可以参看中间的图示部分,有颜色的原点表示聚类中心点,四角星为特征点blabla。然后结合右边的伪代码看
总结:VLAD的算子矩阵存的是对每个聚类中心,在其(最近邻)聚类簇中所有样本(SIFT特征)的残差和。

以VLAD描述子进行图像搜索的例子,对每幅图像的SIFT特征点聚合得到VLAD特征,选择k=16,所以VLAD的维度是16*128
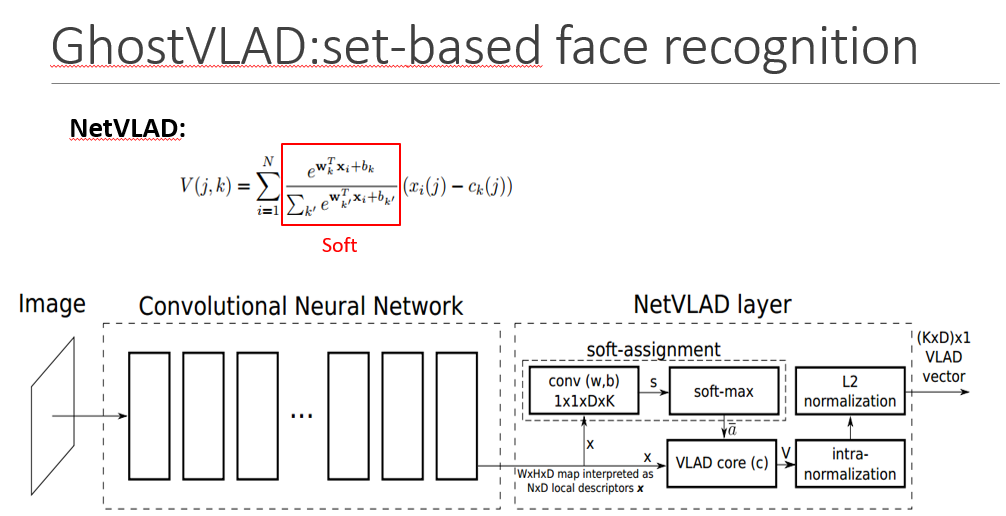
VLAD一般和传统特征一起使用,而netVLAD实现了将CNN和改进后的VLAD结合使用,最开始用在大规模的地点识别问题,任务是从一张图像中快速准确地识别位置。
为了将VLAD能够应用到CNN中,将硬分配ak转化为利用Softmax的软分配,形成可微的结构,从而可以利用卷积操作和反向传播自动求导的功能,实现端到端的训练
在网络中表现为用K个1x1xD的卷积核卷积之后再经过softmax层得到软分配系数,将该系数与残差相乘,最后累加得到V的向量,最后经过两次归一化操作得到维度为KxD的向量
K相当于前面的K个聚类中心,N为局部特征点x的个数,D为x的维度
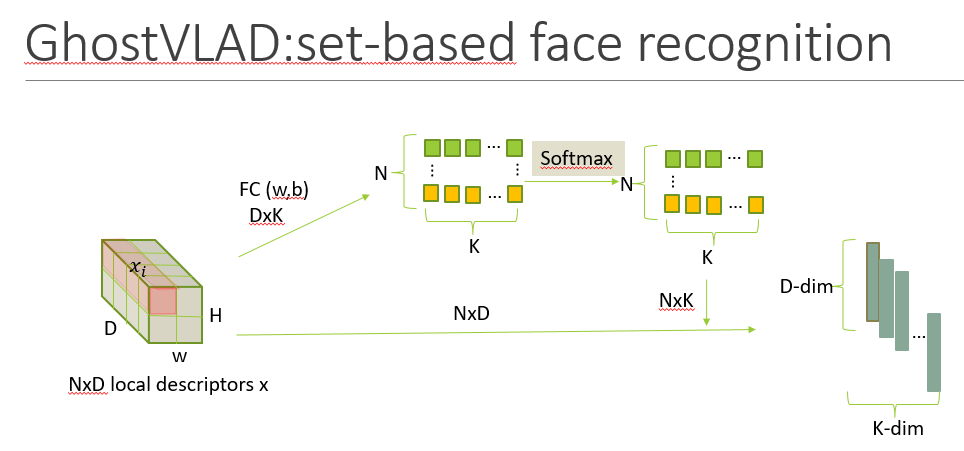
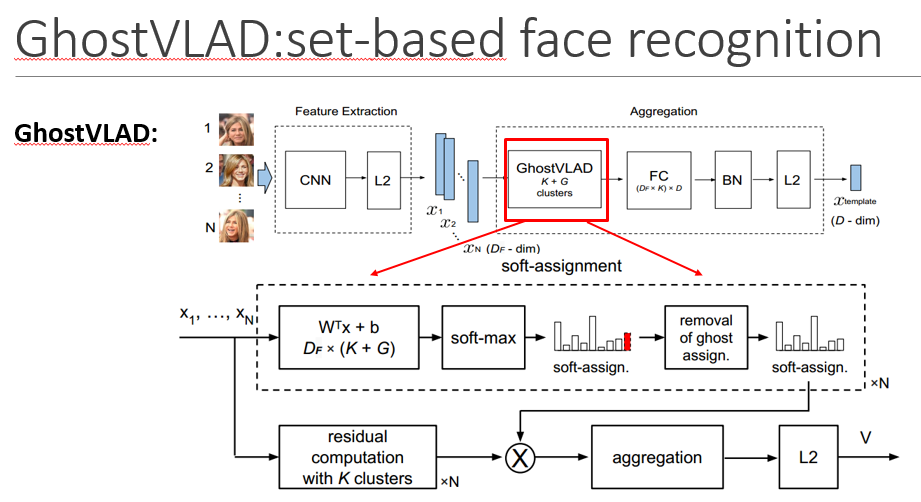
GhostVLAD又是基于NetVLAD的改进,增加了Ghost聚类中心,是指一些假设存在但是实际没有的中心点,就是说在聚合过程去掉这些聚类中心,主要目的是让低质量图片可以归类到这类中心点上,从而在软分配时,对实际的k个聚类中心的得分都降低。
整个网络结构包括两个部分,一个就是特征提取,这一阶段会为每张人脸图片生成人脸特征向量,然后是聚合过程,将所有的单张人脸特征描述子聚合成一个紧凑的集合级的人脸特征向量。FC层是为了计算和内存考虑的降维操作,输出一般D=128

D为最后每个template的维度,T为template的个数

SENet-50和average-pooling一起使用,SE-2表明图像集合的size为2
第一行和第二行展示了人脸特征降维(2048D-128D)不会影响太大。
第2行和第3行表明了,SENet-50表现要优于ResNet-50
K值一般在4到16之间,(太小容易欠拟合,太大容易产生冗余信息和过拟合)9到11行可以看出来性能变化
第8行和3、4行对比,表明在没有降级图像的训练情况下,SE-GV-2的表现优于SE
第9行和2、5行对比,表明在降级图像训练的情况下,SE-GV-2的表现也要由于SE
第6行和第二行表明了计算backbone换成了ResNet,GhostVLAD还是有用的

GhostVLAD中ghost聚类中心的作用,上面一行是G=0,下面是G=1,可以看出ghost聚类中心可以降低低质量图像对最终的特征表示的贡献。

GaitSet

基于集合的步态识别GaitSet,下面的图像是一个完整的行走周期步态轮廓图
作者认为步态轮廓序列中存在步态周期,在周期中每个位置的步态轮廓有着唯一的特征。步态轮廓被扰乱了,也可以通过步态轮廓特征重新的排列他们。因此作者认为一个轮廓外观包含了它的位置信息。这个假设,作者认为步态序列的时序信息是不必要的,可以将步态看着set来提取时序信息,让深度神经网络自身优化去提取并利用这种关系。
作者提出的办法不受帧的排列的影响,并且可以自然地整合来自不同视频的帧,不同的视角、不同的衣服和携带条件

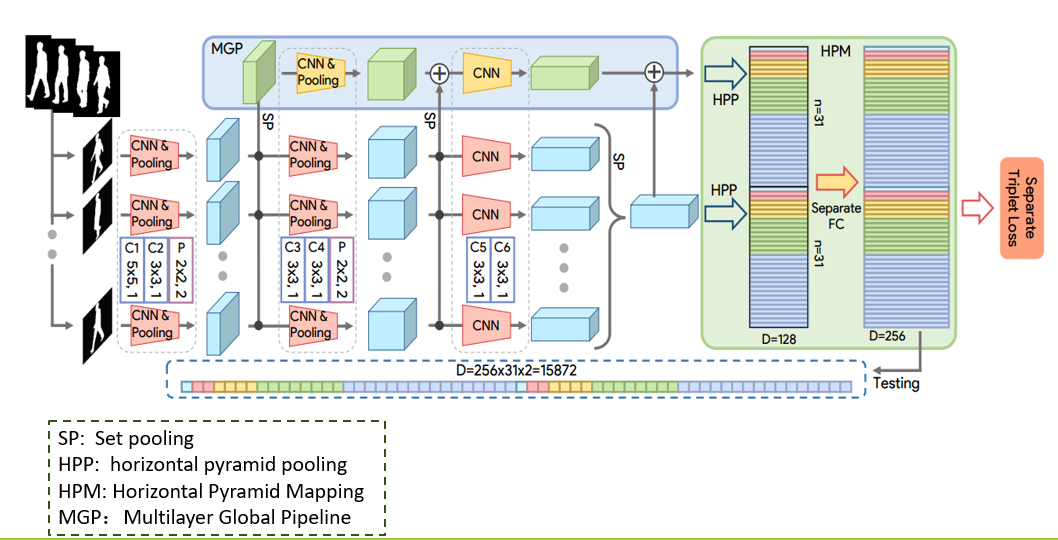
输入时步态的轮廓图集合,首先,CNN用来提取帧级特,然后Set
pooling操作用来将帧级特征聚合成集合级的特征,然后HPM用来将集合级的特征映射到更具有判别力的空间特征得到最终的特征表示。
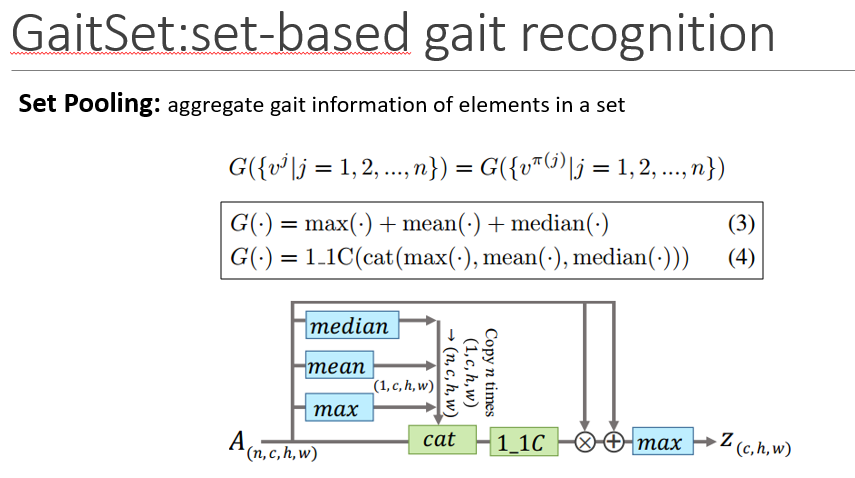
Setpooling是用来整合集合中的步态信息的,所以有一个约束就是由于输入的是集合,应该是置换不变的
主要思想是利用全局信息来学习每个帧级特征图的注意力图,以对其进行细化
全局信息首先是由左侧的统计函数得到的,然后将其与原始特征图一起送入1x1卷积层计算,相当于attention机制,通过在精化的帧级特征映射集合上使用MAX来提取最终的集合级特征z,残差结构可以加速并稳定收敛
max, mean and median are applied on setdimension.
cat means concatenate on thechannel dimension
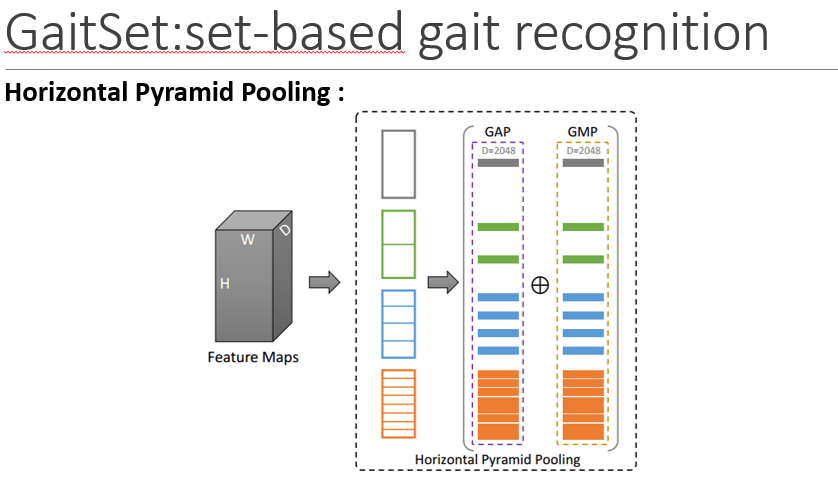
Motivation:HPP 是受SPP启发的,但是是被用来学习在各种尺度上增强人体各部分的具有判别力的信息。
由于区分人体的分布是从头到脚,所以HPP以水平方式将特征图切成多个strip
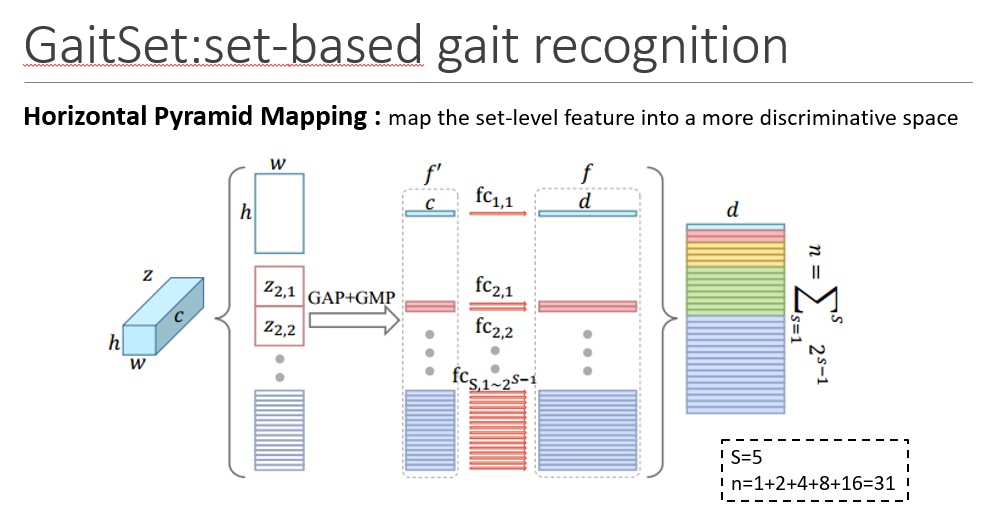
HPM是经过改进的HPP,更适合步态识别任务,
使用不同尺度的strips有不同的感受野和不同空间位置的特征,所以它们使用的是独立的fc层,最后的Fc层是为了将特征映射到更具有判别力的空间
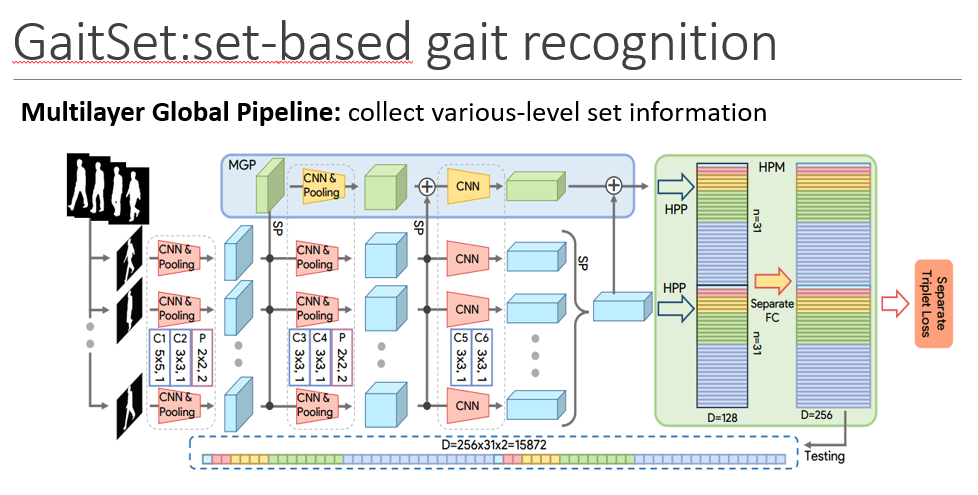
不同的层有不同的感受野,层数越深的感受野越大,主要关注的是更global和粗糙的信息,层数越浅的层关注的是更局部且更精细的信息。不同的层的SP作用也是这样。MGP最后的特征也要被送入HPM层

P表示有多少个人,k表示在这个batch中每个人有多少张训练样本。论文中使用的是8x16和32x16
Online triplet mining
Batch all:计算所有的validtriplet,对hard 和 semi-hardtriplets上的loss进行平均。
- 不考虑easy triplets,因为easytriplets的损失为0,平均会把整体损失缩小
- 将会产生PK(K-1)(PK-K)个triplet,即PK个anchor,对于每个anchor有k-1个可能的positiveexample,PK-K个可能的negativeexamples

NM:6 coat:2 bag:2
each subject has 11 × (6 +2 + 2) = 110 sequences
在测试阶段,所有的三种行走状态的前4个NM的序列作为gallery,剩余的6个序列被分成三个probe set中
3 walking conditions and 11 views
Total:124 subjects
NM表示正常的行走状态
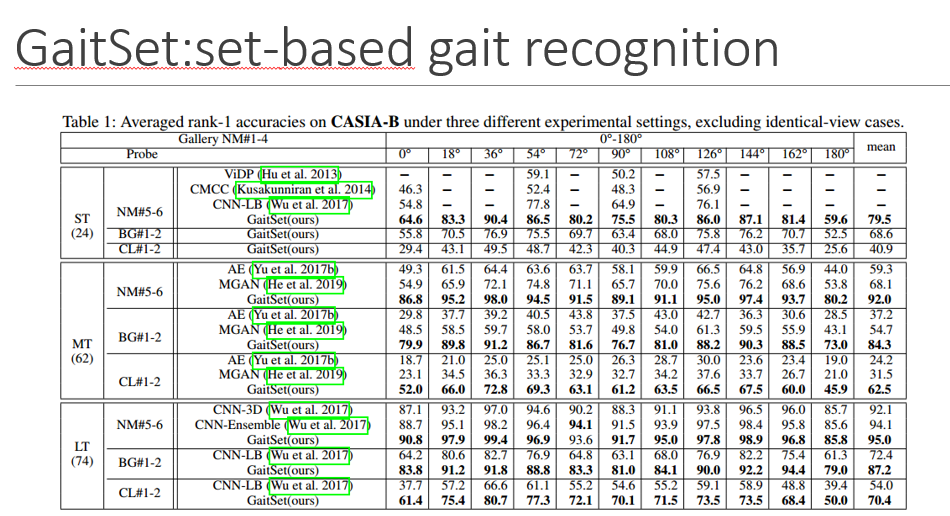
0、90、180度准确率最低,可能的原因是步态信息不仅包含与步行方向平行的步幅信息,如90°时最明显可以观察到的步幅信息,还包括与行走方向垂直的步态信息,如可以观察到的身体或手臂的左右摆动最明显的是0°或180°
而36度和144度这两种信息都包含了,所以识别效果较好
1、2行显示了set和GEI两种模式的影响,GEI是指将步态轮廓
第2、3行显示的是HPM的权重共享还是不共享对识别的影响
3-8行显示了其他条件相同时,SP的不同设置对最终识别的影响,括号为表现最好的