图像质量评估(IQA)
Convolutional Neural Networks for No-Reference Image Quality Assessment
Paper:Convolutional Neural Networks for No-Reference Image Quality …
code:-
Author:Le Kang,Peng Ye,Yi Li,David Doermann
time:2014CVPR
Abstract
In this work we describe a Convolutional Neural Network (CNN) to accurately predict image quality without a reference image. Taking image patches as input, the CNN works in the spatial domain without using hand-crafted features that are employed by most previous methods. The network consists of one convolutional layer with max and min pooling, two fully connected layers and an output node. Within the network structure, feature learning and regression are integrated into one optimization process, which leads to a more effective model for estimating image quality. This approach achieves state of the art performance on the LIVE dataset and shows excellent generalization ability in cross dataset experiments. Further experiments on images with local distortions demonstrate the local quality estimation ability of our CNN, which is rarely reported in previous literature.
翻译:在这篇论文中,将会介绍如何在不需要参考图像的情况下利用CNN来准确预测图像质量(NR-IQA)。输入为图像的patch,CNN不需要利用手工特征,该网络包括一个卷积层和最大、最小池化层、两个全连接层和输出节点。在网络结构中,特征学习和回归被集成到一个优化过程中,这样模型预测图像质量会更有效。该方法在LIVE数据集上达到了state-of-the-art,并且在交叉数据集实验中泛化能力优异,对局部失真图像的进一步实验表明了CNN的局部质量评估能力,这在以前的文献中很少报道。
Contribution
- 修改了网络结构,可以更有效的图像的质量特征,估计图像质量更准确
- 提出了一个新的框架,可以让特征学习和预测在局部区域进行,而先前的工作都是在整个图像上得到累积特征以获得用于估计总体质量的统计数据。而我们的方法可以在小的patch(比如32x32)上估计质量评分。
Summary
本篇论文就是对灰度图像,首先执行对比度归一化,然后采样不重叠的patch,使用CNN来估计每个patch的质量得分和平均patch得分来估计图像的质量分数,CNN就是一个很简单的回归网络。需要注意的是,本文采用的不是对整体进行对比度归一化,而是在局部的patch上做对比度归一化(contract normalization),因为在全局做平均的归一化会有性能损失。归一化不仅可以缓解早期工作中使用sigmoid神经单元引起的饱和问题,还使网络对光照和对比度变化具有鲁棒性,值得注意的是,在某些应用中将亮度和对比度的变化也看作失真,但这里主要关注的是图像质量下降(模糊、压缩和加性噪声)引起的失真。
Quality Aware Network for Set to Set Recognition
paper:Quality Aware Network for Set to Set Recognition
code:https://github.com/sciencefans/Quality-Aware-Network`caffe`
Author: Yu Liu,JunJie Yan,Wanli Ouyang
time: 2017CVPR
Abstract
This paper targets on the problem of set to set recognition, which learns the metric between two image sets. Images in each set belong to the same identity. Since images in a set can be complementary, they hopefully lead to higher accuracy in practical applications. However, the quality of each sample cannot be guaranteed, and samples with poor quality will hurt the metric. In this paper, the quality aware network (QAN) is proposed to confront this problem, where the quality of each sample can be automatically learned although such information is not explicitly provided in the training stage. The network has two branches, where the first branch extracts appearance feature embedding for each sample and the other branch predicts quality score for each sample. Features and quality scores of all samples in a set are then aggregated to generate the final feature embedding. We show that the two branches can be trained in an end-to-end manner given only the set-level identity annotation. Analysis on gradient spread of this mechanism indicates that the quality learned by the network is beneficial to set-to-set recognition and simplifies the distribution that the network needs to fit. Experiments on both face verification and person re-identification show advantages of the proposed QAN. The source code and network structure can be downloaded at GitHub.
翻译:本文主要针对set-to-set的识别问题,学习两个图像集合之间的metric。每个set中的图片属于同一类,由于一个set中的图像可以互补,因此有望在实际应用中提高精度,但是不能保证每个样本的质量,质量差的样本会对最终的结果产生不好的影响。本文提出质量感知网络(QAN)来解决这个问题,每个样本的质量可以自动学习,尽管在训练阶段没有明确提供这些信息。网络含有两个分支,第一个分支为每个样本提取appearance特征,另一个分支为每一个样本预测质量得分,一个set总所有样本的特征和质量分数都会聚合以生成最终的feature embedding。本论文表明,在只给定set-level的标注时,才能以端到端的的方式训练两个分支。对该机制的梯度扩展的分析表明,网络学习到的质量评估有利于set-to-set的识别,并简化了网络需要拟合的数据分布,在人脸验证和行人重识别任务上表现良好。
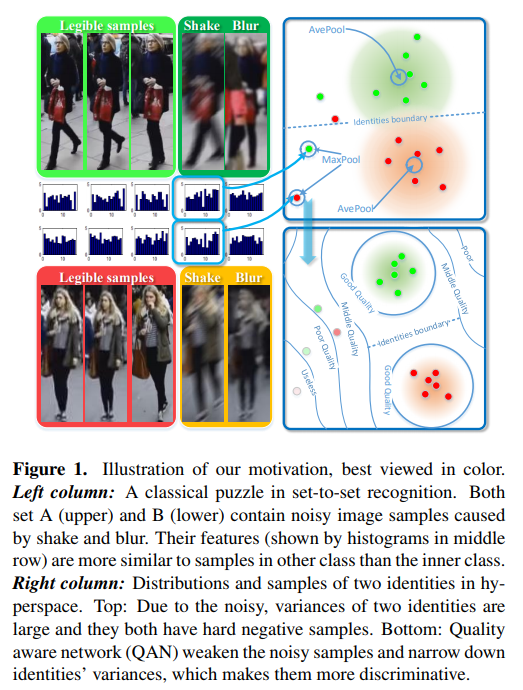
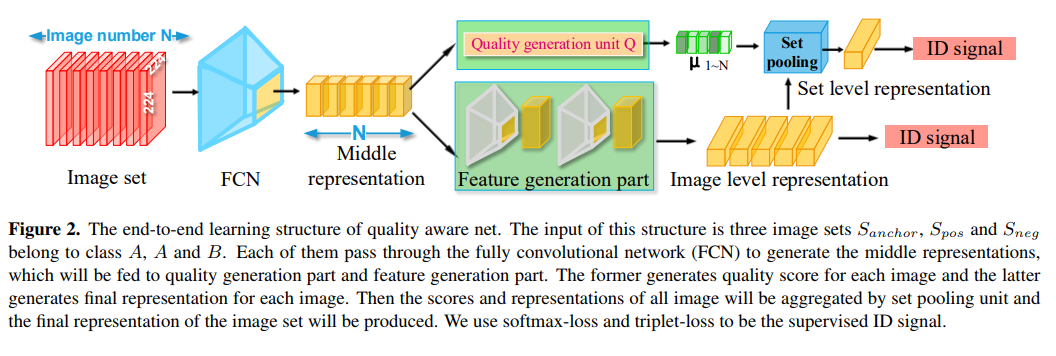
Contribution
- The proposed quality aware network automatically generates quality scores for each image in a set and
leads to better representation for set-to-set recognition - We design an end-to-end training strategy and demonstrate that the quality generation part and feature generation part benefit from each other during back propagation.
- Quality learnt by QAN is better than quality estimated by human and we achieves new state-of-the-art performance on four benchmarks for person re-identification and face verification.
Summary
人脸质量评估(FQA)
Automatic Face Image Quality Prediction
paper:Automatic Face Image Quality Prediction
code:
Author:
time: 2017
Abstract
Face image quality can be defined as a measure of the utility of a face image to automatic face recognition. In this work, we propose (and compare) two methods for automatic face image quality based on target face quality values from (i) human assessments of face image quality (matcherindependent), and (ii) quality values computed from similarity scores (matcher-dependent). A support vector regression model trained on face features extracted using a deep convolutional neural network (ConvNet) is used to predict the quality of a face image. The proposed methods are evaluated on two unconstrained face image databases, LFW and IJB-A, which both contain facial variations with multiple quality factors. Evaluation of the proposed automatic face image quality measures shows we are able to reduce the FNMR at 1% FMR by at least 13% for two face matchers (a COTS matcher and a ConvNet matcher) by using the proposed face quality to select subsets of face images and video frames for matching templates (i.e., multiple faces per subject) in the IJB-A protocol. To our knowledge, this is the first work to utilize human assessments of face image quality in designing a predictor of unconstrained face quality that is shown to be effective in cross-database evaluation.
翻译:面部图像质量可以被定义为面部图像对自动面部识别的效用的度量。在这项工作中,我们提出(并比较)两种基于目标面部质量值的自动面部图像质量的方法,这两种方法来自(i)面部图像质量的人体评估(匹配器依赖性),以及(ii)根据相似性得分计算的质量值(匹配器 - 依赖)。使用深度卷积神经网络(ConvNet)提取的面部特征训练的支持向量回归模型用于预测面部图像的质量。所提出的方法在两个无约束的人脸图像数据库LFW和IJB-A上进行评估,这两个数据库都包含具有多个质量因子的面部变化。对所提出的自动面部图像质量测量的评估表明,通过使用所提出的面部质量来选择面部子集,我们能够将两个面部匹配器(COTS匹配器和ConvNet匹配器)的1%FMR的FNMR降低至少13%。用于匹配IJB-A协议中的模板(即,每个主题的多个面部)的图像和视频帧。据我们所知,这是第一项利用人体面部图像质量评估来设计无约束面部质量预测器的工作,该预测器在跨数据库评估中显示出有效性。
Contribution
Summary
Face Image Quality Assessment Based on Learning to Rank
paper:Face Image Quality Assessment Based on Learning to Rank
code: 开源了
Author:
time: 2015年
Abstract
Face image quality is an important factor affecting the accuracy of automatic face recognition. It is usually possible for practical recognition systems to capture multiple face images from each subject. Selecting face images with high quality for recognition is a promising stratagem for improving the system performance. We propose a learning to rank based framework for assessing the face image quality. The proposed method is simple and can adapt to different recognition methods. Experimental result demonstrates its effectiveness in improving the robustness of face detection and recognition .
翻译:
人脸图像质量是影响自动人脸识别准确率的重要因素。实际识别系统通常可能从每个subject捕获多个面部图像,选择具有高质量的面部图像用于识别是用于改善系统性能的一个策略,我们提出了基于learning to rank的框架来评估面部图像质量,该方法简单,可以适应不同的识别方法,实验结果证明了其在提高人脸检测和识别鲁棒性方面的有效性。
Method
图像预处理过程
按常理来说,图片中只有人脸区域的像素点才能被用来评估面部质量好坏,所以我们首先如下图检测到人脸,然后将其resize到68x68大小。然后送入CNN中作为输入,我们使用眼角和嘴角,因为这两处的关键点可以很清晰,并包含了大部分的人脸区域。

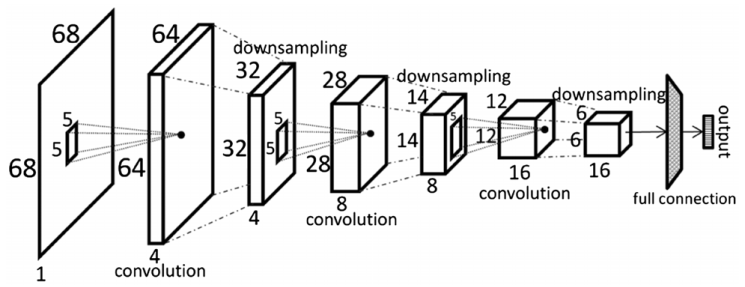
利用上图中简单的CNN作为关键点检测网络,在LFW数据集中挑选了10000张作为训练集,剩下的作为测试集,图一中的(b)为预测的关键点。
对人脸区域进行归一化,并消除面内旋转,首先计算中心点C和半径r(包含了所有关键点的最小圆),然后以2.4rx4r的矩形R来代替如图一中的(c)所示,这样就可以计算矩形的角度
面部质量评估
目前主要有两种面部质量评估的办法:
- 利用特定的性质,比如分辨率、角度、光照强度来量化面部图像质量
- 将一张面部图像来与“标准”的人脸图像进行比较,利用它们之间的差异来度量面部质量
但是这两种办法都不灵活,也缺乏实用性,因为它们都没有考虑到人脸识别算法的可能的差异性,比如对于能很好处理遮挡情况的人脸识别系统,Fig1(g)要比Fig(f)更好,而对于能很好处理姿态差异的人脸识别系统,Fig(f)要比Fig(g)好。应该以相对的方式来评估面部图像质量。
基于上述考虑,提出一个简单灵活的基于learning to rank的方法来进行面部质量评估,大致来讲就是,比如对于一个人脸识别方法在数据集A上的表现要好于在数据集B上的表现,那么可以认为数据集A中图像质量要高于数据集B中图像的质量,然后同一数据集中的图像的质量分数应该被看做是相同的。具体公式论文中有描述,这里不详细写。但是作者利用的是显式映射函数而不是kernel SVM来计算RQS(Rank based Quality Score)
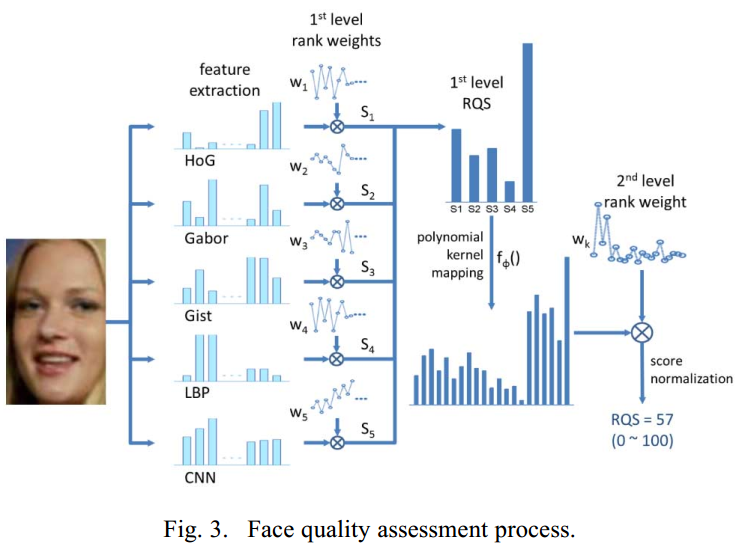
Summary
从论文的结果上来看还是很好的,而作者开源的代码在实际应用场景中也表现得很鲁棒

模板
标题
paper:
code:
Author:
time:Abstract
翻译:
Contribution
Summary