原文链接:FaceNet:A unified embedding for face recognition and clustering
简介
FaceNet,可以直接将人脸图像映射到欧几里得空间,空间距离的长度代表了人脸图像的相似性,只要该映射空间生成,人脸识别、验证和聚类等任务就可以轻松完成。FaceNet在LFW数据集上的准确率为99.63%,在YouTube Faces 数据集上准确率为95.12%。
前言
FaceNet采用的是通过卷积神经网络学习将图像映射到欧几里得空间,空间距离之间和图片相似度相关:同一个人的不同图像的空间距离很小,不同人的图像的空间距离较大,只要该映射确定下来,相关的人脸识别任务就变得简单。
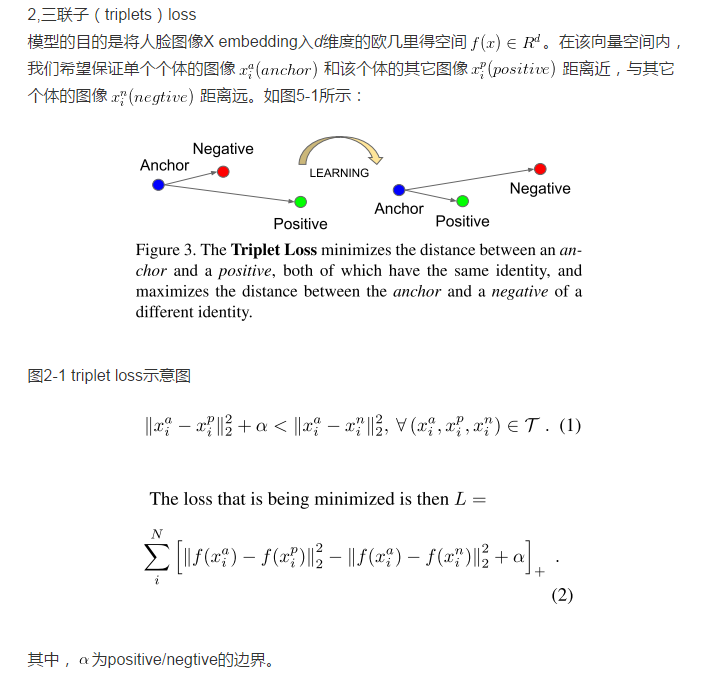
当前存在的基于深度神经网络的人脸识别模型使用了分类层:中间层为人脸图像的向量映射,然后以分类层作为输出层,这类方法的缺点就是不直接和效率不高。与当前方法不同,FaceNet直接使用基于triplets的LMNN(最大边界近邻分类)的loss函数训练神经网络,网络直接输出为128维度的向量空间。选取的triplets包含两个匹配脸部缩略图(为紧密裁剪的脸部区域,不用使用2d、3d对齐以及放大转换等预处理)和一个非匹配的脸部缩略图,loss函数目标是通过距离边界区分正负类。
本文中,探索了两类深度卷积神经网络,第一类为Zeiler&Fergus研究中使用的神经网络,包含多个交错的卷积层、非线性激励函数,局部相应归一化和最大池化层。我们额外的添加了一些1x1xd的卷积层。第二种结构是基于Inception model,这种网络利用了一些不同的卷积层和池化层并行和级联响应。我们发现这些模型可以减小20倍以上的参数数量,并且可能会减少FLOPS数量。
triplet loss的启发是传统loss函数趋向于将有一类特征的人脸图像映射到同一个空间,而triplet loss尝试将一个个体的人脸图像和其他人脸图像分开。
总结
- 三元组的目标函数并不是这篇论文首创,我在之前的一些Hash索引的论文中也见过相似的应用。可见,并不是所有的学习特征的模型都必须用softmax。用其他的效果也会好。
- 三元组比softmax的优势在于
- softmax不直接,(三元组直接优化距离),因而性能也不好。
- softmax产生的特征表示向量都很大,一般超过1000维。
- FaceNet并没有像DeepFace和DeepID那样需要对齐。
- FaceNet得到最终表示后不用像DeepID那样需要再训练模型进行分类,直接计算距离就好了,简单而有效。
- 论文并未探讨二元对的有效性,直接使用的三元对。